
你是不是也经常这样?
- 每天想刷热搜,但微博、百度、头条来回切换,太麻烦
- 只关心特定关键词(比如“马斯克”、“特斯拉”、“钢铁侠”),不想被无关热点淹没
- 希望有人能帮你汇总全网热点,定时推送到微信,还能语音播报
为了解决这个问题,我用 Python 写了一个 JARVIS 热搜雷达。它每天自动抓取微博和百度热搜,智能去重合并,生成日报、推送企业微信、提供交互式网页看板,还能语音播报关键词命中情况。全程自动化,就像钢铁侠的智能管家。
🛠️ 功能简介
✅ 自动采集
- 每日 08:00 定时抓取微博热搜榜 + 百度热搜榜
- 自动去重合并,保留原始平台标识
✅ 智能预警
- 配置关注的关键词(如“特斯拉”、“SpaceX”、“马斯克”)
- 命中时通过企业微信机器人实时推送提醒
✅ 日报生成
- 每日生成 Markdown 格式的日报,包含:
- 关键词命中雷达
- 全网 Top 15 热搜列表
- 统计数据
✅ 交互式网页看板(Streamlit)
- 按日期筛选热搜
- 多关键词搜索过滤
- 一键导出结果为 Markdown 或 Excel
- Plotly 动态趋势图:展示关键词近 7 天上榜次数和总热度
- 内置语音播报:点击按钮,JARVIS 亲口念出当天热点
✅ 自动清理
- 只保留最近 7 天的数据文件,不占磁盘空间
✅ 一键启动
- 提供两个
.bat脚本:-
start_web.bat:启动网页交互界面 -
start_background.bat:启动后台定时任务
-
🧰 技术栈
- Python 3.8+
-
数据采集:
requests+ 解析各平台接口(微博、百度) -
定时调度:
schedule库 -
网页前端:
Streamlit+Plotly动态图表 -
数据处理:
pandas - 语音播报:浏览器 Web Speech API(通过 Streamlit 嵌入)
-
配置文件:
config.py集中管理关键词、Webhook、保留天数 - 文件清理:基于文件修改时间的自动清理脚本
📁 项目结构
hot_news_aggregator/
├── crawlers/ # 采集模块
│ ├── weibo.py # 微博热搜爬虫
│ └── baidu.py # 百度热搜爬虫
├── data/ # 每日原始数据(JSON)
├── output/ # 生成的日报(Markdown)
├── utils/ # 工具函数
│ └── cleaner.py # 自动清理旧文件
├── app.py # Streamlit 网页应用
├── main.py # 定时调度核心
├── config.py # 配置文件(关键词、Webhook等)
├── start_web.bat # 一键启动网页脚本
├── start_background.bat # 一键启动后台定时脚本
├── requirements.txt # 依赖列表
└── README.md # 项目说明
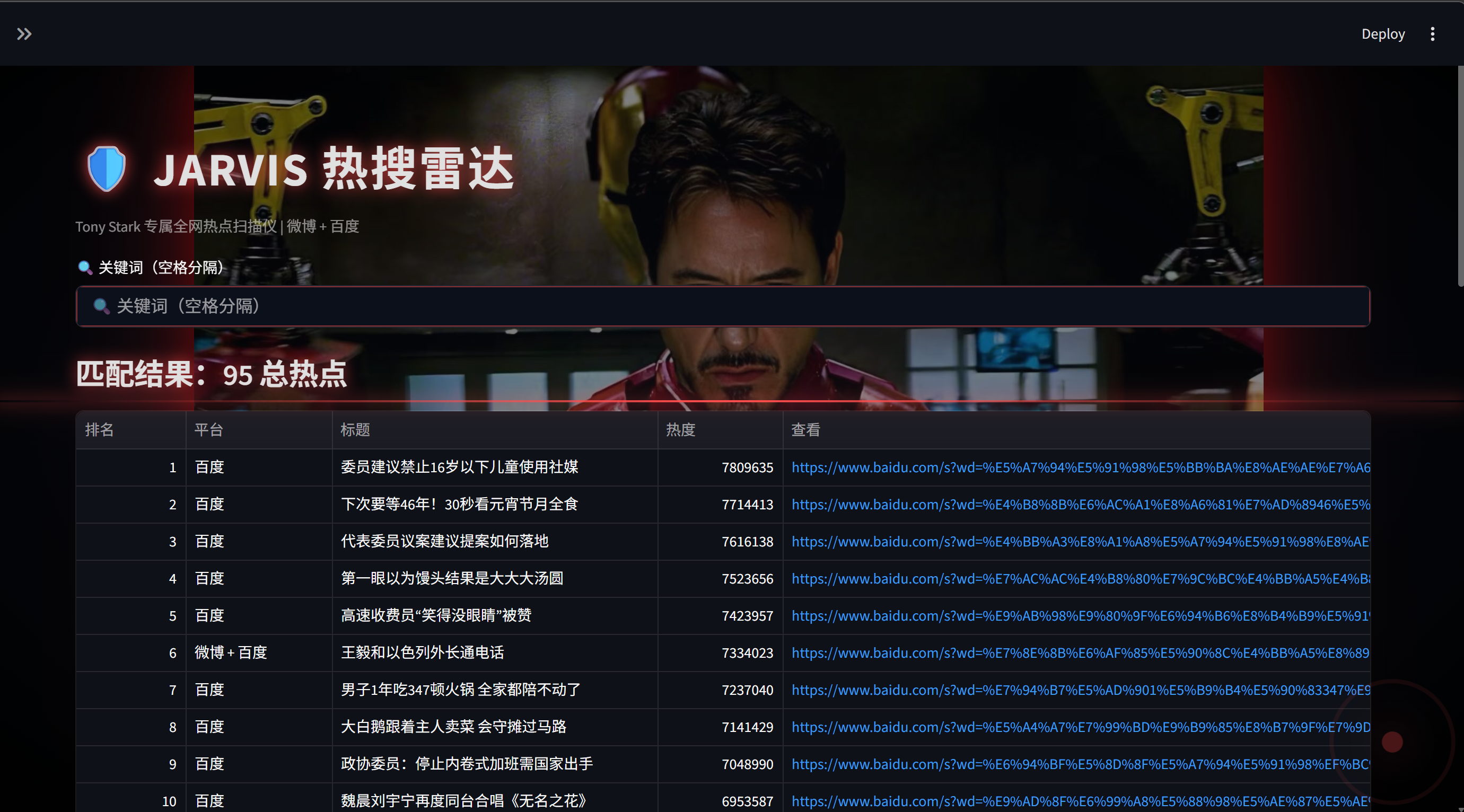
📸 效果展示
网页主界面(钢铁侠风格)

关键词趋势图(Plotly 动态图表)
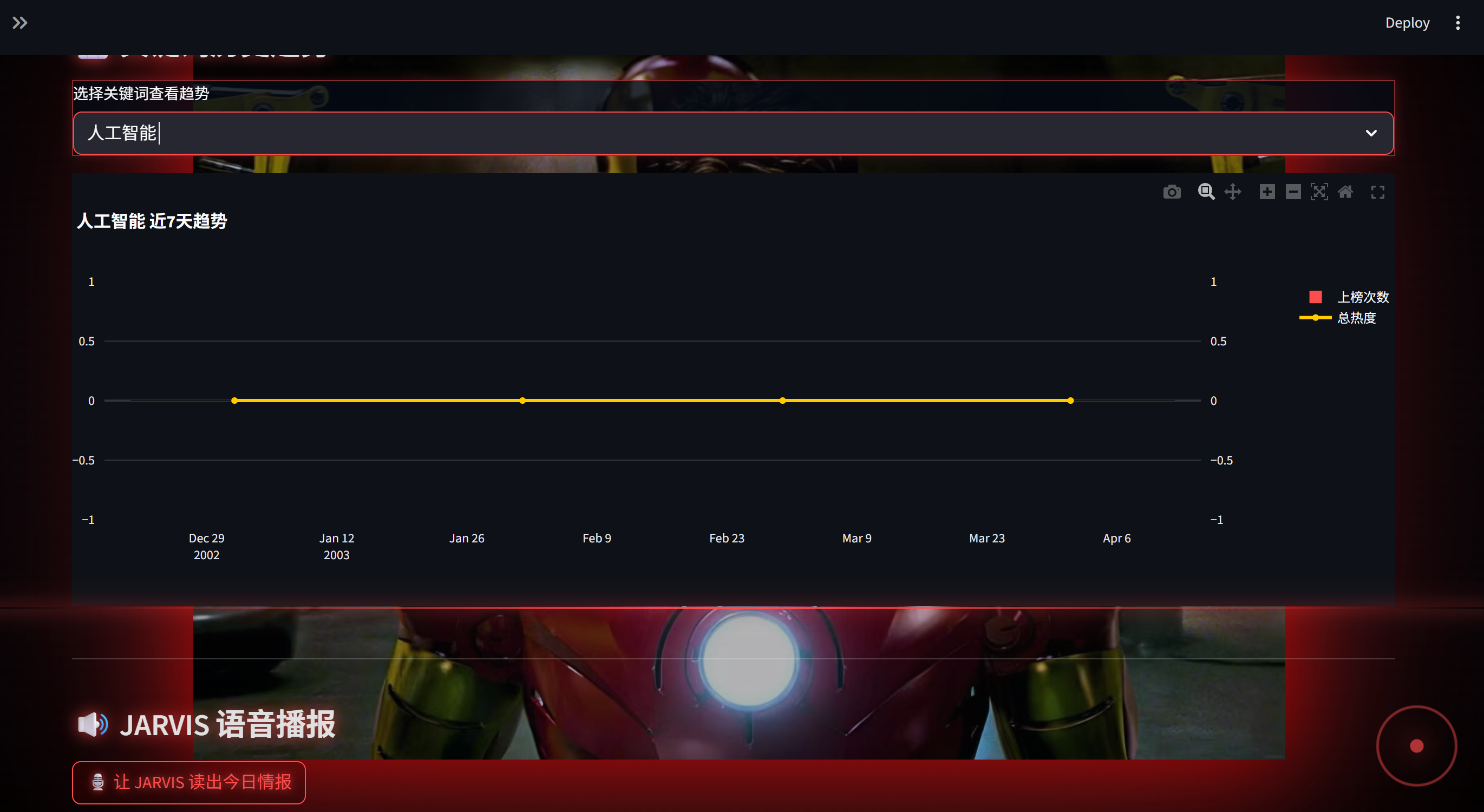
关键词趋势图之所以显示为零,原因其实很简单:
- “钢铁侠”是小众词汇:在每天数以千计的热搜话题中,“钢铁侠”、“马斯克”这类特定关键词出现的频率本就不高,大多数时候热搜榜都被娱乐八卦、社会热点等大众话题占据。
- 数据量有限:目前仅抓取了少量数据作为功能验证,样本较少,命中概率自然更低。
- 但JARVIS依然在线:就像电影里那样,即使暂时没有信号,JARVIS也永远在后台守护,一旦捕捉到你的关注词,它会第一时间推送到你手中。你可以换成你喜欢的行业动态、明星赛事,它就会为你精准追踪。
致敬Tony Stark和Robert Downey Jr:这个项目的灵感正是来自那位天才发明家和他天才般的演出。

侧边栏和底部功能示例(语言切换、语音播报)
扩展和预留接口示例
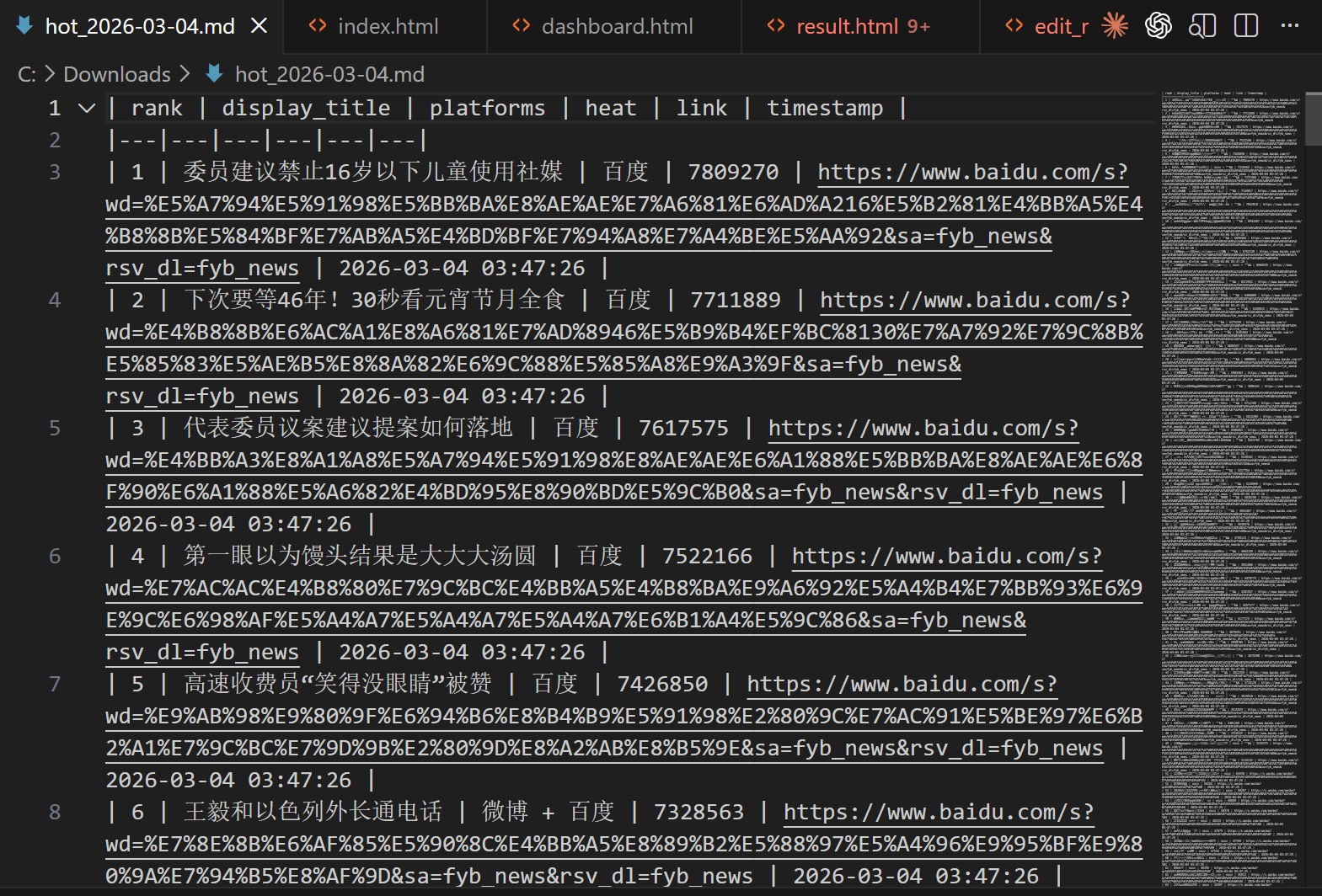
日报 Markdown 示例
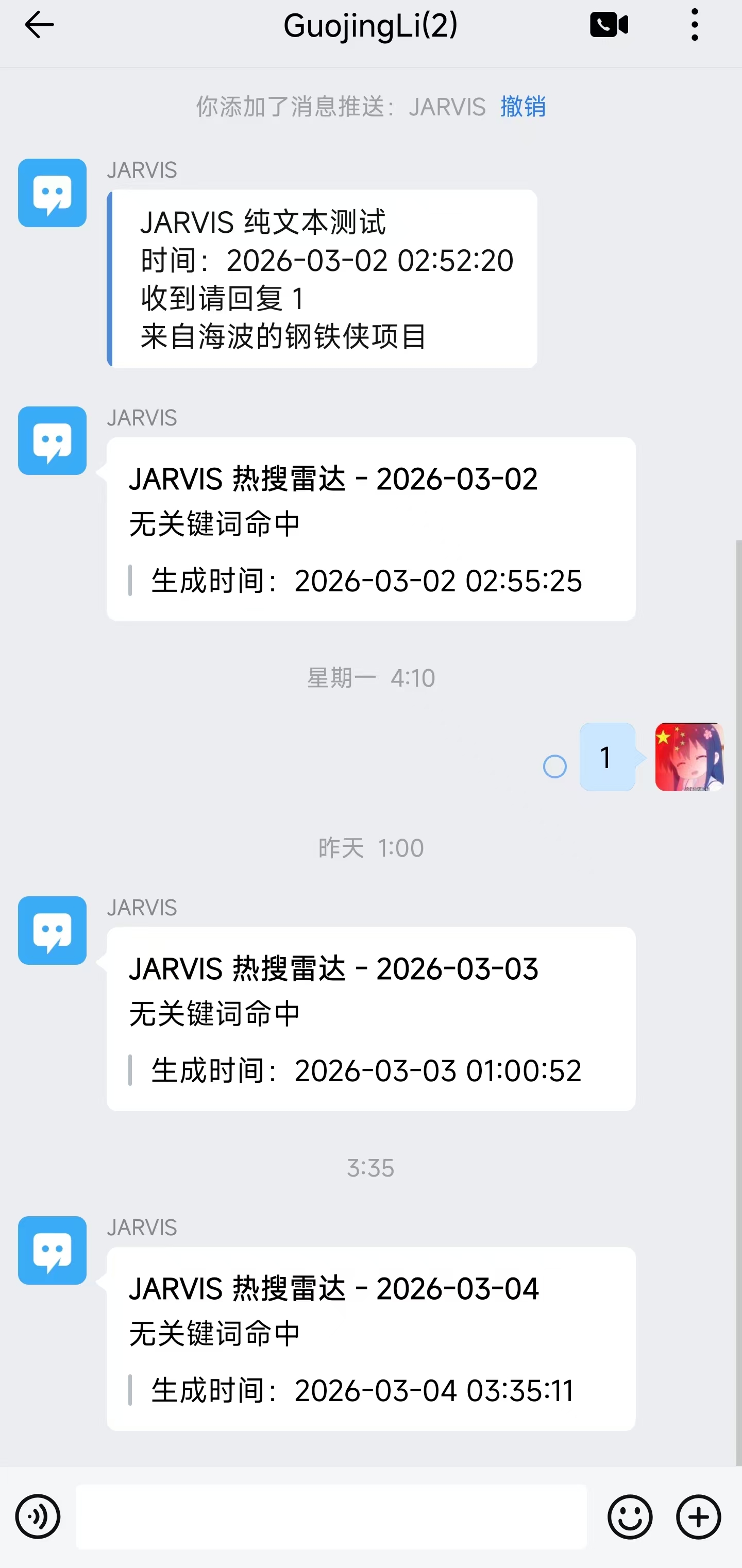
企业微信推送示例
🚀 快速上手
1. 克隆项目
git clone https://github.com/liguojing112/hot-news-aggregator.git
cd hot-news-aggregator
2. 安装依赖
pip install -r requirements.txt
3. 配置
编辑 config.py,设置关注的关键词、企业微信机器人 Webhook(可选)、数据保留天数。
# 你关注的关键词(命中即推送)
KEYWORDS = ["特斯拉", "SpaceX", "马斯克"]
# 企业微信机器人 Webhook(留空则不推送)
ENTERPRISE_WECHAT_WEBHOOK = "https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxxx"
# 数据保留天数
KEEP_DAYS = 7
4. 运行
🌐 网页模式(推荐)
双击 start_web.bat,或执行:
streamlit run app.py
浏览器自动打开,你可以搜索、看趋势、听语音、导出结果。
⏰ 后台定时模式
双击 start_background.bat,程序将在后台运行,每天 08:00 自动抓取并推送。(窗口可最小化,不要关闭)
💡 开发经验与心得
1️⃣ 爬虫:合法合规是第一原则
刚开始做爬虫时,我也担心法律风险。但经过调研和实践,我明白:爬取公开数据用于个人学习,低频、非商业、注明来源,是完全合法的。 本项目仅抓取无需登录的热搜榜单,每天一次,且注明数据来源,完全符合 robots.txt 和商业道德。如果未来有更高频率的需求,我会主动联系平台申请授权或使用官方 API。
2️⃣ 定时任务:schedule 库真香
之前一直用操作系统的定时任务(cron / 任务计划程序),但跨平台麻烦。改用 Python 的 schedule 库后,代码里直接写定时逻辑,配合无限循环,简单可靠,还能在终端实时看到下次执行时间。
3️⃣ 网页界面:Streamlit 是原型神器
这是我第一次用 Streamlit 写完整 Web 应用,体验非常好:代码量极少,自带美观组件,内置缓存、主题、部署。搭配 Plotly 做交互图表,几分钟就能做出一个可用的数据看板。非常适合个人工具类项目快速验证。
4️⃣ 语音播报:Web Speech API 的小惊喜
想让 JARVIS 真正“说话”,最开始考虑用 pyttsx3 但需要额外安装。后来发现 Streamlit 可以嵌入 HTML 和 JavaScript,直接调用浏览器原生的 SpeechSynthesis API,一行 JS 就能实现语音播报,而且音质自然。多利用前端能力,往往比后端方案更轻巧。
5️⃣ 配置集中化:告别硬编码
把所有可变的参数(关键词、Webhook、保留天数)放进 config.py,用户修改时无需翻代码,自己也容易维护。如果未来想做成多用户在线版,甚至可以设计为从数据库读取配置。
6️⃣ 自动清理:别让硬盘爆炸
每天抓取的数据虽然不大,但日积月累也会占用空间。写了一个简单脚本,根据文件修改时间自动删除过期文件,让项目始终保持整洁。
⚖️ 法律合规说明
本项目严格遵守网络爬虫的道德规范与法律法规:
- 仅抓取 无需登录即可访问 的公开热搜数据
- 设置 低频抓取(每日一次),不影响目标网站正常运行
- 遵守 robots.txt 协议,仅抓取允许访问的内容
- 注明数据来源,尊重原平台的劳动成果
- 仅用于 个人学习研究,不涉及任何商业用途或数据售卖
- 目前仅爬取三次以验证功能,数据量极小
如有任何版权或合规问题,欢迎联系作者沟通处理。
📌 项目地址
GitHub: https://github.com/liguojing112/hot-news-aggregator.git
欢迎 Star、Fork、提 Issue 或 PR!
💡 后续计划
- [ ] 增加更多数据源(知乎热榜、抖音热点)
- [ ] 支持用户自定义抓取时间和频率
- [ ] 添加邮件推送选项
- [ ] 部署到云服务器,做成公共 Web 服务(会先获取平台授权)
🤝 欢迎交流
如果你也有信息聚合的需求,或者对爬虫、数据可视化感兴趣,欢迎在评论区留言,或到 GitHub 上找我。我们一起让 JARVIS 变得更聪明!
从一个小想法到完整的全栈情报系统,JARVIS 热搜雷达让我感受到了创造带来的快乐。希望它也能帮到你。
May the code be with you. 🛡️
最后修改于



 8
8


可以的