
看到一个体育数据 RAG 系统遇到的瓶颈:为什么单一 RAG 不够用?我的扩展工作流思路分享
最近看到一个帖子,楼主分享了自己基于 20 年体育数据(可能是 NBA 或其他联赛的统计、新闻、比赛记录)构建的 RAG 系统。系统用 LlamaIndex 处理文档、Ollama 做本地 LLM,还有一些自定义 embedding 和检索优化。简单查询如“某个球员的生涯数据”或“球队历史战绩”效果不错,答案带来源、准确率高。但楼主吐槽了复杂查询时的痛点,比如“某个球员最近两场比赛的表现对比”,系统就容易召回不准、幻觉或不完整。
我觉得这个帖子很有代表性,因为它暴露了单一 RAG 在实际场景中的局限性。作为一个专注 Advanced RAG 和文档处理的开发者,我也遇到过类似问题。下面我来分析一下帖子的痛点、我的思考,以及我自己想出来的解决思路,希望对大家有启发。欢迎评论区讨论,你们在做 RAG 系统时,有没有被类似瓶颈卡过?
帖子的核心痛点:单一 RAG 应付不了“多步推理 + 动态查询”
那个提出问题的楼主系统的基础是经典 RAG:查询 → 检索 → 生成。但在体育数据这种时间敏感、需要对比的场景下,问题就出来了:
- 时间逻辑处理缺失:比如“最近两场比赛的表现”,系统不知道怎么先确定“最近两场是哪天”(需要动态计算时间),直接检索容易召回过时或无关数据。
- 召回不完整或低相关:单一检索步容易漏掉“对比”所需的多个数据点(e.g., 两场比赛的得分、助攻、命中率),结果答案只列数据,没分析差异/趋势。
- 上下文丢失和幻觉:多轮查询时,系统状态不一致(e.g., 第一轮召回一场,第二轮召回另一场,但没连起来对比),容易生成“半吊子”答案或虚构内容。
- 整体响应不智能:用户得手动拆解问题(先问“最近两场是哪天”,再问“表现数据”,最后问“对比”),否则系统卡住。楼主提到优化 embedding 和检索后还是没完全解决,评论区也有人反馈类似:复杂查询召回率低,系统“聪明但不稳”。
这些痛点不是模型不够强,而是 RAG 本身的“一刀切”模式在“动态、多步、推理型”查询上力不从心。楼主试了加时间过滤器,但没彻底解决——这其实已经超出“纯 RAG”的范畴了。
我的思考:问题已超出单一 RAG,需要扩展到“工作流 + 多代理”框架
我自己做 Advanced RAG 系统时,也遇到过类似瓶颈。传统 RAG 擅长“事实检索 + 生成”,但像体育数据这种需要“时间拆解 + 多源搜索 + 对比分析”的场景,单一 RAG 就成了瓶颈。它像一个“万金油”工具,但没法处理“链条式”逻辑。
关键洞察:
- RAG 不应该再是“主角”,而应该降级为一个“节点”或“外部信息源”(类似文章提到的 MCP,模型上下文协议)。
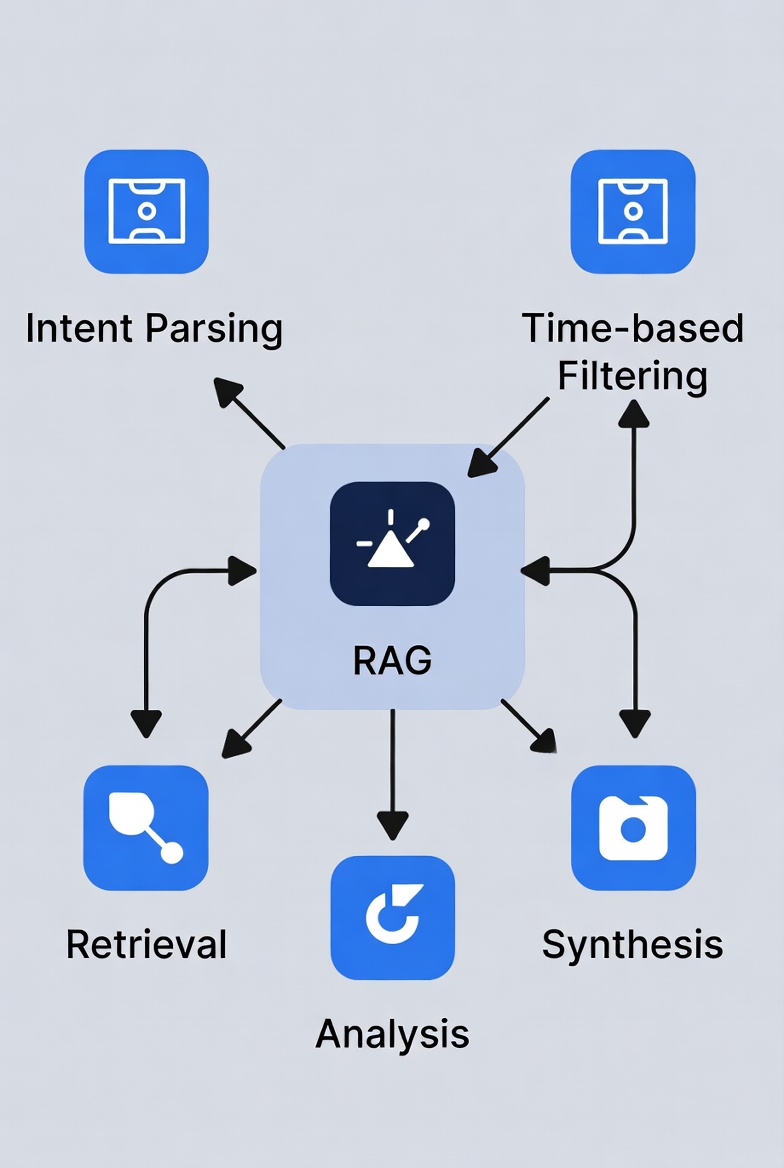
- 整个系统需要扩展到工作流(workflow)框架,把问题拆成多个代理/节点,每个节点专注一件事:意图拆解、时间过滤、检索、分析、整合。
- 这样才能解决“矛盾点”:代理间状态一致、数据不污染、意图不跑偏。同时,不同问题类型可以用不同工作流,灵活性高。
- 为什么不全靠 LLM prompt 堆?因为 LLM 意图模糊时容易崩(hallucination),而工作流加约束(schema 校验)能强制执行规则。
总之,从理论上,单一 RAG 适合简单查询;复杂场景必须“工作流化”,RAG 只负责它最擅长的“检索召回”。
我的解决思路:设计多类型工作流,RAG 只做节点
基于这个思考,我在自己的项目里试了用 LangGraph(或类似 CrewAI/Autogen)建“树状/图状工作流”。核心是分类问题类型,然后路由到对应流。下面举楼主“球员最近两场比赛表现对比”的例子,展示一个简单工作流:
-
意图拆解节点(LLM 代理):
接收用户查询“X 球员最近两场比赛的表现对比”。
输出:拆成子任务,如“确定最近两场时间”“检索两场数据”“对比分析”。
为什么先这个?避免 RAG 直接上,减少无关召回。
-
时间过滤节点(LLM + 工具代理):
用 LLM + 日历/数据库 API 计算“最近两场” = 具体日期/比赛 ID。
输出:结构化 JSON { "player_id": "X", "game_dates": ["2026-03-08", "2026-03-05"] }。
这里加被动校验:输出必须有日期数组,否则重试。
-
多 RAG 查询节点(RAG 作为源):
对每个日期跑一次 RAG 检索(带时间过滤 metadata)。
输出:两场比赛的表现数据 JSON { "game1": { "points": 25, "assists": 8, ... }, "game2": { ... } }。
这里 RAG 只负责“信息获取”,不生成答案。
-
分析对比节点(LLM 代理):
接收上一步数据,用 LLM 计算差值、趋势、总结(e.g., “得分提升 10%,但失误增加”)。
输出:对比报告 + 溯源(每数据点带来源)。
加自检 prompt:“输出前检查是否有对比逻辑,如果缺失就修复”。
-
整合输出节点(最终 LLM):
汇总所有,生成用户友好答案。
加全程校验:确保有溯源 + 无 hallucination。
工作流设计要点:
- 用 LangGraph 建图:每个节点是代理/工具,边是条件路由(e.g., “如果时间不确定,回拆解节点”)。
- 多类型流:简单事实 → 直 RAG;对比型 → 上边流;趋势型 → 加统计节点(Pandas 计算平均)。
- 约束:关键节点用 schema 被动校验(Pydantic),其余 LLM 自检 prompt。
- 好处:减少返工 50%+,token 消耗可控(只在必要节点多轮)。
这个思路不是万能,但比单一 RAG 稳多了。



好文章
谢谢,我也是在学习中,如果有不全面的地方,欢迎讨论指教